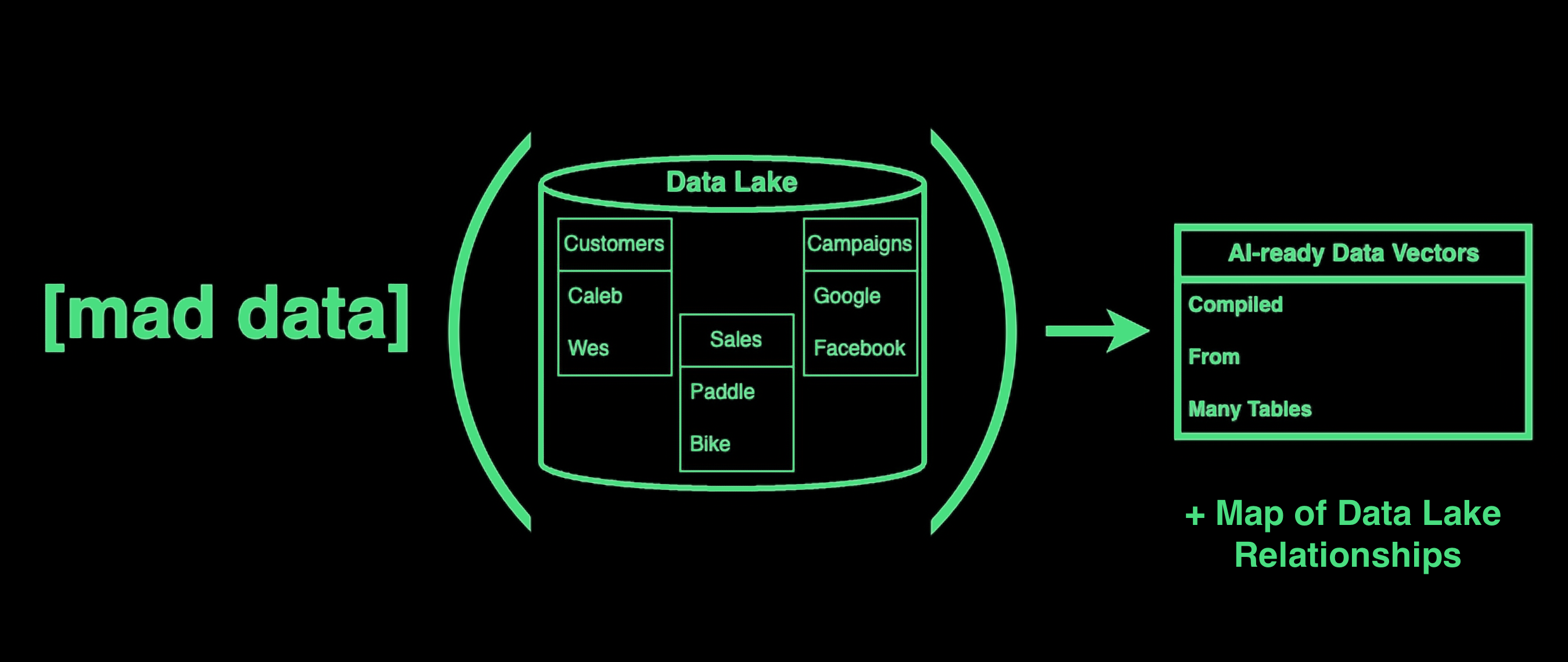
Your ML team needs data vectors
[How we work]
> Clearly-scoped contracts
We transform Data Lakes (or DBs) into ML-ready Data vectors, and provide ER Diagrams
> Fast data understanding with Kurve
Our sister company Kurve develops a producted (backed by Stanford Research) to automatically derive entity relationships, allowing us to quickly understand how tables connect in Data Lakes.
> Maintanable data transformations with GraphReduce
Instead of writing unmanageable multi-hundred-line SQL, we use an open-source library called GraphReduce to build maintainable data transformation pipelines.